连续强刚了几天爬虫,大致摸清了这套框架的基本流程和最最最基本使用。
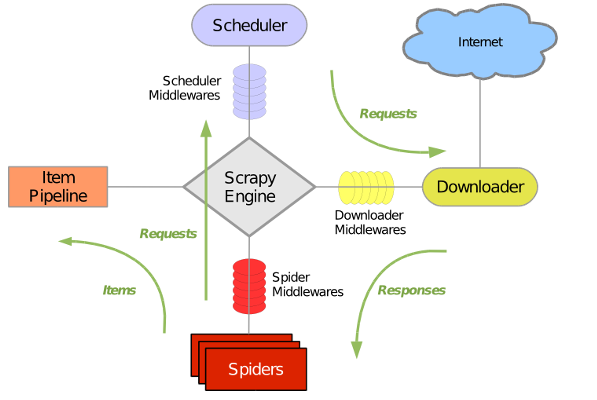
Scrapy框架的运行流程
很多教程都使用如上这个图。确实可以很清晰的看出该框架的运行机制。
首先,当创建完一只Spider的时候,我们将启动这只蜘蛛。即给Spider开始运行。Spider会将第一批url发送给引擎(Engine) (当我们创建完一只蜘蛛时,会生成一批url,就是第一批URL) .
然后接着Engine就负责把这个安排给Scheduler(调度器)去处理。当处理完成的时候,(这里的处理只是生成request,并不是发包以后返回respond) ,将生成的request再返回给引擎。
再接着,引擎把request传递给Downloader(下载器),由它进行将每个request的返回值(respond)下载回来。将接收到的返回值,传给引擎。
引擎再把这个返回值传给spider,spider进行处理(分类出item(数据)和继续爬取的url),依旧交还给引擎。
最后引擎将得到的item传给管道处理,将url给调度器进行处理。这样一次完整的爬去就结束了。
从上述流程中,会发现引擎对数据的传递是原封不动的传递。
创建一只爬虫 在项目路径下使用该命令可以创建一只爬虫。
1 2 scrapy startproject First_Spider #创建爬虫项目 scrapy genspider baidu www.baidu.com #创建一个基本的爬虫 baidu为爬虫名字,www.baidu.com是要爬取的域名
在spider文件夹里会生成一个baidu.py
1 2 3 4 5 6 7 class BaiduSpider (scrapy.Spider) : name = 'baidu' allowed_domains = ['www.baidu.com' ] start_urls = ['http://www.baidu.com/' ] def parse (self, response) : pass
1 2 # 启动爬虫 scrapy crawl baidu
提取数据 前面流程分析中,数据是由Spider进行分类,传给专门item管道处理用来保存。。
1 2 3 4 5 6 7 class FirstSpiderItem (scrapy.Item) : meta = scrapy.Field() title = scrapy.Field()
那么回到Spider中的代码应该将数据分离出来
1 2 3 4 5 6 7 8 9 10 11 12 13 def parse (self, response) : soup = BeautifulSoup(response.body,'html.parser' ) meta_all = soup.find_all('meta' ) for i in meta_all: item = FirstSpiderItem() item['meta' ] = i.name print("*" *12 ) print(item['meta' ]) print("*" * 12 ) yield item
这里并不需要使用BF进行解析,response本身就支持使用CSS选择选择器和Xpath的方式提取数据。将获取到的数据保存起来使用如下命令
1 2 3 4 5 6 scrapy crawl baidu -o result.json
一个实例来继续学习 爬去腾讯招聘网站的数据。
先定义一下需要哪些数据。依旧是在item里定义需要获取到的字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class TencentItem (scrapy.Item) : positionname = scrapy.Field() positionlink = scrapy.Field() positionType = scrapy.Field() peopleNum = scrapy.Field() workLocation = scrapy.Field() publishTime = scrapy.Field()
然后到spider去写分离数据的部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 class TencentpostionSpider (scrapy.Spider) : name = 'tencentPostion' allowed_domains = ['tencent.com' ] start_urls = ['http://hr.tencent.com/position.php?&start=' ] offset=0 base_url = "http://hr.tencent.com/position.php?&start=" def parse (self, response) : for each in response.xpath("//tr[@class='even'] | //tr[@class='odd']" ): item = TencentItem() item['positionname' ] = each.xpath("./td[1]/a/text()" ).extract()[0 ] item['positionlink' ] = each.xpath("./td[1]/a/@href" ).extract()[0 ] if len(each.xpath("./td[2]/text()" ))==0 : item['positionType' ] = '' else : item['positionType' ] = each.xpath("./td[2]/text()" ).extract()[0 ] item['peopleNum' ] = each.xpath("./td[3]/text()" ).extract()[0 ] item['workLocation' ] = each.xpath("./td[4]/text()" ).extract()[0 ] item['publishTime' ] = each.xpath("./td[5]/text()" ).extract()[0 ] yield item if self.offset < 3120 : self.offset += 10 yield scrapy.Request(self.base_url + str(self.offset), callback=self.parse) if len(response.xpath("//a[@class='noactive'and @id='next']" )): return next = response.xpath("//a[@id='next']/@href" ).extract()[0 ] yield scrapy.Request(self.base_url + next, callback=self.parse)
如上代码,可以看出response本身就支持xpath语法进行数据提取,每一个xpath提取出来的数据都是一个列表。而且是select类型,需要使用extract()转换成字符串。利用yield的能力继续发送下一个请求,Request函数callback参数指的是定义调用哪个parse函数进行处理。
item类只是将数据存起来,实质上就是一个字典。前面提到item是给item管道进行处理,现在来编写管道文件。
1 2 3 4 5 6 7 8 9 10 import json class TencentPipeline(object): def __init__(self): self.filename = open("result.json", "w") def process_item(self, item, spider): text = json.dumps(dict(item), ensure_ascii=False) + ",\n" self.filename.write(text) return item def close_spider(self,spider): self.filename.close()
__init__是管道类的构造函数。close_spider在爬虫关闭的时候执行。
当编写了管道,需要在setting中开启。
1 2 3 4 5 ITEM_PIPELINES = { 'Tencent.pipelines.TencentPipeline' : 300 , }
执行爬虫
1 scrapy crawl tencentPostion
发现不需要加-o参数了。就可以直接把文件保存出来。也就是说数据在管道里已经保存起来了。所以我们可以在管道里写各种的处理方法,使得完成一些数据分析。
总结 之前学习urllib、request、bs4这些库事已经可以做到提取数据,分析数据了。那么为什么还要用这个框架?是因为真的很方便。不需要自己构造发包,请求头参数等可以在setting里设置,并且可以随机选择一些请求头来逃避反爬虫机制。而回一下如果使用前面学习的类库,就得一步一步构造请求包。当然,前面学习的可以说是爬虫的原理,最基本的掌握了,使用这框架会更容易一些。
Author:
zhhhy
Permalink:
http://yoursite.com/2019/04/05/scrapy/
License:
Copyright (c) 2019 CC-BY-NC-4.0 LICENSE
Solgan:
Do you believe in DESTINY?